flowchart LR A[Domain data] --> G[Global Model] A --> C(Clustering) C --> K1[Subset model 1] C --> K2[Subset model 2] C --> Kn[Subset model k] G --> P1[Inference] K1 --> P2[Inference] K2 --> P2 Kn --> P2 P1 --> AC[Performance comparison] P2 --> AC
Subset Modeling
A Domain Partitioning Strategy for Data-efficient Machine Learning
Method
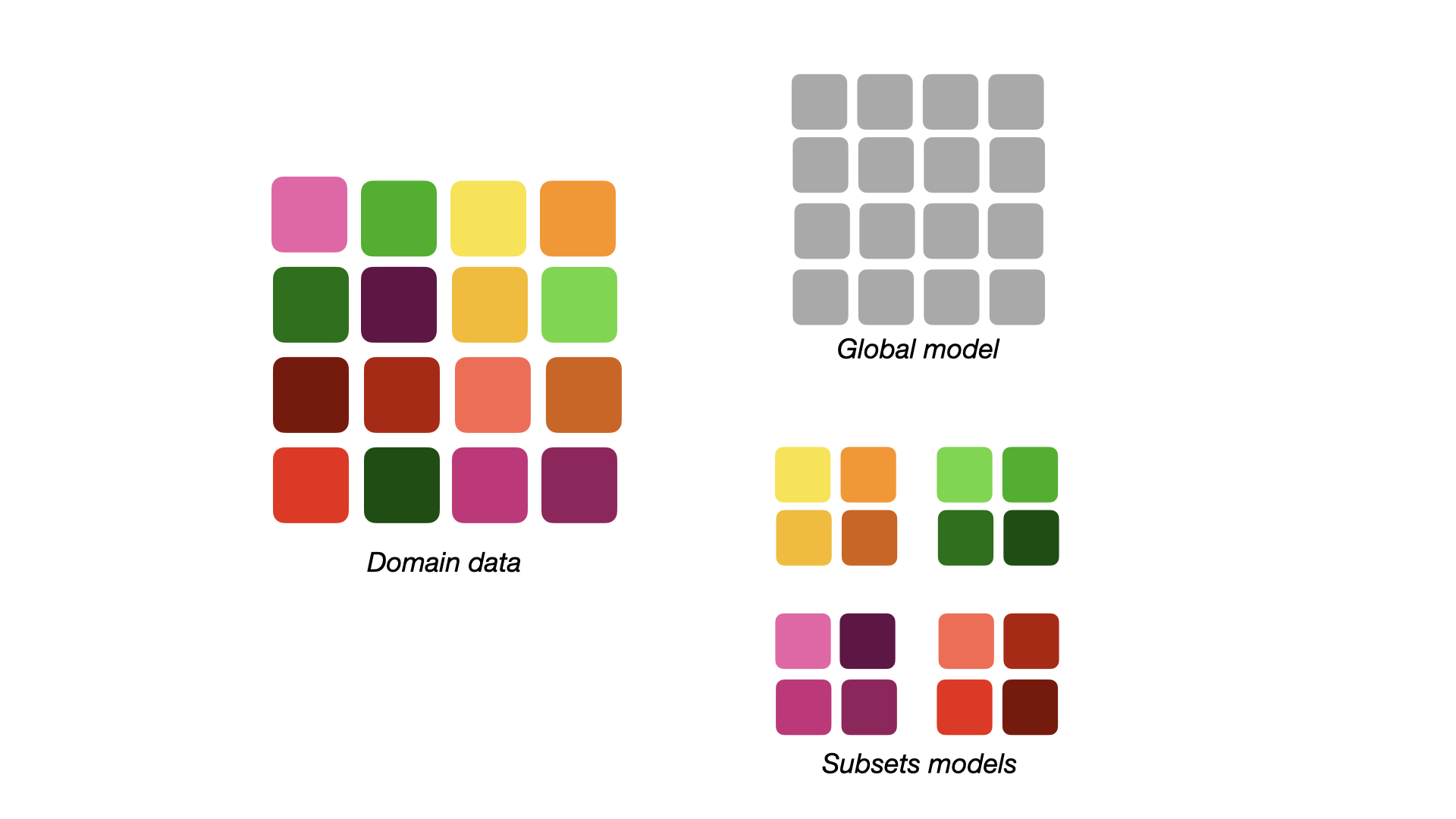
GeoLifeCLEF 2023 competition
- Large-scale training dataset of 5M plant occurrences
- Validation set of 5K plots
- Test set with 20K plots
- Baseline model Spatial Random Forest (PA), trained with Presence-Absence data and longitude/latitude as covariates