x <- c(2,2,3,4,4,5,6,7,3,7,7,1,6,7,8)
rle(x)Run Length Encoding
lengths: int [1:12] 2 1 2 1 1 1 1 2 1 1 ...
values : num [1:12] 2 3 4 5 6 7 3 7 1 6 ...Some days ago I was trying to count how many times consecutive sequences with values higher than a reference appears in a data frame.
For example:
\(x = {2,2,3,4,4,5,6,7,3,7,7,1,6,7,8}\)
On \(x\), how many times values higher than four appears in consecutive sequences with three or more elements?
Two times: the sequences \(5,6,7\) and \(6,7,8\).
But how to figure this out with R?
Base R has an interesting function called Run Length Encoding: rle(x). Let’s see how this works with our example.
x <- c(2,2,3,4,4,5,6,7,3,7,7,1,6,7,8)
rle(x)Run Length Encoding
lengths: int [1:12] 2 1 2 1 1 1 1 2 1 1 ...
values : num [1:12] 2 3 4 5 6 7 3 7 1 6 ...The rle function returns a list of lengths and values. The “lengths” says how many times the “values” appears. The number two appears two times in sequence, then the number three appears one time, followed by a fours appearing two times, and so on…
I created a little function (trle) to perform the following task: with a vector x, count consecutive sequences of length equal or higher than l that contains values equal or higher than v.
x is higher or equal to v. This will return a vector of true and false values.
rle function over the sequence of true/false values.
value is equal to TRUE AND (&) have length higher than l.
Let’s test it with our example.
trle(x, l = 3, v = 4)[1] 2There are probably better and faster ways to implement this. I focused on being simple and readable.
In climatology there is an indicator called Warm Spell Duration Index (WSDI). A warm spell consist of at least six consecutive days with maximum temperatures higher than the climatological normal maximum temperature. A more formal definition can be found here.
We can get some temperature values with the brclimr package for Rio de Janeiro, Brazil.
rio <- brclimr::fetch_data(
code_muni = 3304557,
product = "brdwgd",
indicator = "tmax",
statistics = "mean",
date_start = as.Date("2020-01-01"),
date_end = as.Date("2020-12-31")
)
head(rio, 10)# A tibble: 10 × 2
date value
<date> <dbl>
1 2020-01-01 36.0
2 2020-01-02 31.1
3 2020-01-03 27.9
4 2020-01-04 28.5
5 2020-01-05 28.4
6 2020-01-06 34.1
7 2020-01-07 35.8
8 2020-01-08 32.8
9 2020-01-09 33.4
10 2020-01-10 33.7Let’s assume the reference value as 30 Celsius degrees. How many sequences of six days or more had temperatures equal or higher than 30?
trle(x = rio$value, l = 6, v = 30)[1] 3This happened three times on 2020. Try to find them at the graph bellow:
library(ggplot2)
library(scales)
ggplot(data = rio, aes(x = date, y = value)) +
geom_line(color = "purple", alpha = .7) +
geom_point(color = "purple", alpha = .7) +
geom_hline(yintercept = 30, color = "red", alpha = .7) +
theme_classic()
Would be nice if the function returned also when those sequences happened, right? We can change our little function a little bit to return the dates and actual lengths of those sequences, adding an index vector i as argument.
trle2 <- function(x, i, l, v){
1 x_logical <- x >= v
2 rle_list <- rle(x_logical)
3 rle_df <- data.frame(
length = rle_list$lengths,
value = rle_list$values
)
4 rle_df$pos_2 <- cumsum(rle_df$length)
rle_df$pos_1 <- rle_df$pos_2 - rle_df$length + 1
5 rle_df <- data.frame(
pos_1 = i[rle_df$pos_1],
pos_2 = i[rle_df$pos_2],
length = rle_df$length,
value = rle_df$value
)
6 res <- subset(rle_df, value == TRUE & length >= l)
7 res$value <- NULL
8 rownames(res) <- NULL
9 return(res)
}x is higher or equal to v. This will return a vector of true and false values.
rle function over the sequence of true/false values.
pos_1) and end (pos_2) positions of each sequence. The end position is the cumulative sum of the lengths. The start position is equivalent to the end position minus the length plus one.
i and the length and values of the sequences
value is equal to TRUE AND (&) have length higher than l.
value variable.
res <- trle2(x = rio$value, i = rio$date, l = 6, v = 30)
res pos_1 pos_2 length
1 2020-01-06 2020-01-12 7
2 2020-01-26 2020-02-03 9
3 2020-02-15 2020-02-21 7To see that on the graph, we can use some lubridate functions. First, we create a list of date intervals.
library(lubridate)
intervals <- as.list(lubridate::interval(res$pos_1, res$pos_2))Then, we check if the dates are within those intervals.
rio$test <- rio$date %within% intervals
head(rio, 10)# A tibble: 10 × 3
date value test
<date> <dbl> <lgl>
1 2020-01-01 36.0 FALSE
2 2020-01-02 31.1 FALSE
3 2020-01-03 27.9 FALSE
4 2020-01-04 28.5 FALSE
5 2020-01-05 28.4 FALSE
6 2020-01-06 34.1 TRUE
7 2020-01-07 35.8 TRUE
8 2020-01-08 32.8 TRUE
9 2020-01-09 33.4 TRUE
10 2020-01-10 33.7 TRUE And plot it!
ggplot(data = rio, aes(x = date, y = value)) +
geom_line(color = "purple", alpha = .7) +
geom_point(aes(color = test), alpha = .7) +
geom_hline(yintercept = 30, color = "red", alpha = .7) +
scale_color_manual(values=c("#999999", "#E69F00")) +
theme_classic() +
theme(legend.position = "bottom", legend.direction = "horizontal")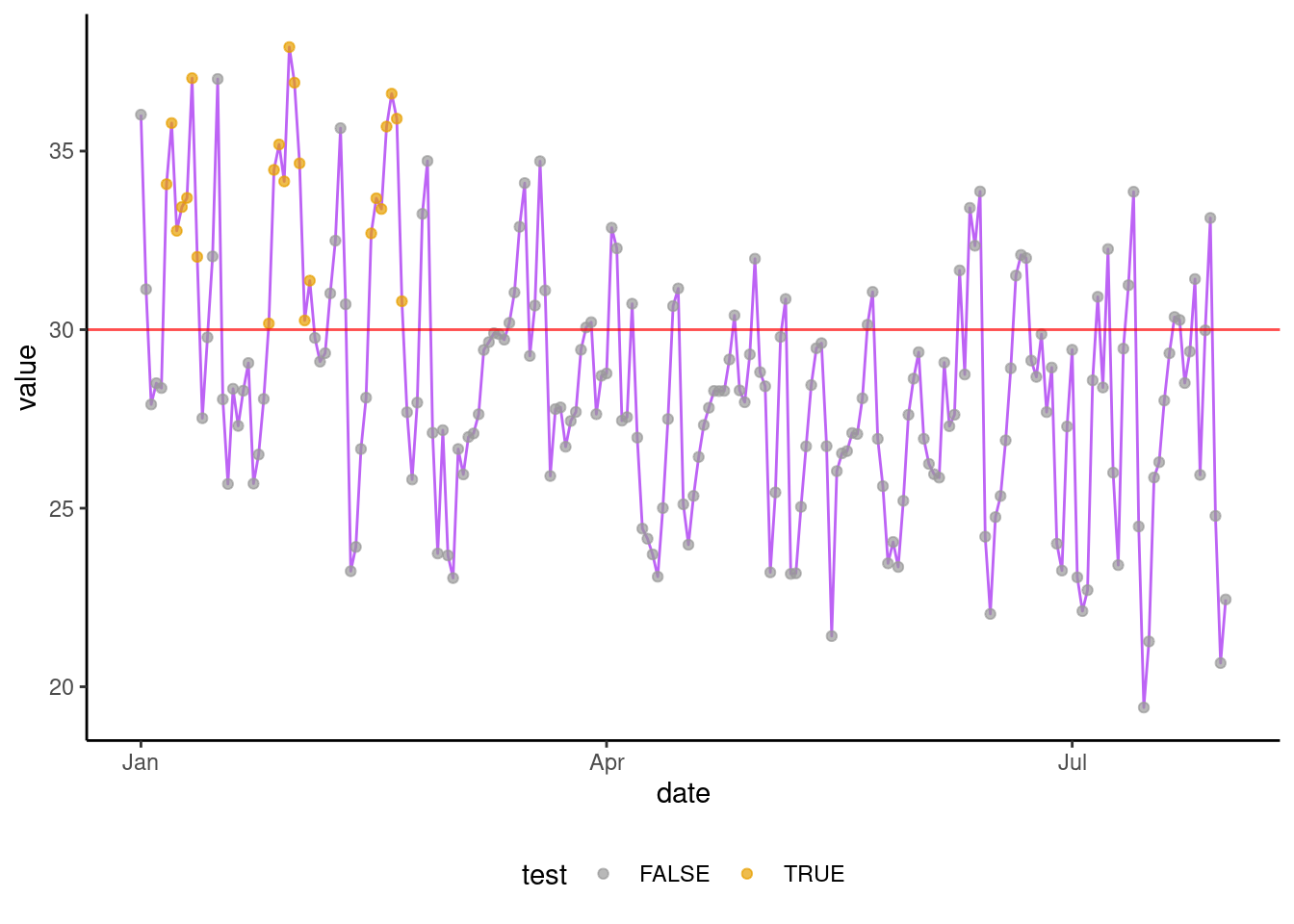
sessionInfo()R version 4.3.2 (2023-10-31)
Platform: x86_64-pc-linux-gnu (64-bit)
Running under: Ubuntu 22.04.3 LTS
Matrix products: default
BLAS: /usr/lib/x86_64-linux-gnu/blas/libblas.so.3.10.0
LAPACK: /usr/lib/x86_64-linux-gnu/lapack/liblapack.so.3.10.0
locale:
[1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
[3] LC_TIME=en_CA.UTF-8 LC_COLLATE=en_US.UTF-8
[5] LC_MONETARY=en_CA.UTF-8 LC_MESSAGES=en_US.UTF-8
[7] LC_PAPER=en_CA.UTF-8 LC_NAME=C
[9] LC_ADDRESS=C LC_TELEPHONE=C
[11] LC_MEASUREMENT=en_CA.UTF-8 LC_IDENTIFICATION=C
time zone: Europe/Paris
tzcode source: system (glibc)
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] lubridate_1.9.3 scales_1.2.1 ggplot2_3.4.4
loaded via a namespace (and not attached):
[1] bit_4.0.5 gtable_0.3.4 jsonlite_1.8.7 dplyr_1.1.4
[5] compiler_4.3.2 tidyselect_1.2.0 assertthat_0.2.1 arrow_14.0.0
[9] yaml_2.3.7 fastmap_1.1.1 R6_2.5.1 labeling_0.4.3
[13] generics_0.1.3 brclimr_0.1.2 knitr_1.45 htmlwidgets_1.6.2
[17] backports_1.4.1 checkmate_2.3.0 tibble_3.2.1 munsell_0.5.0
[21] pillar_1.9.0 rlang_1.1.2 utf8_1.2.4 xfun_0.41
[25] bit64_4.0.5 timechange_0.2.0 cli_3.6.1 withr_2.5.2
[29] magrittr_2.0.3 digest_0.6.33 grid_4.3.2 rstudioapi_0.15.0
[33] lifecycle_1.0.4 vctrs_0.6.4 evaluate_0.23 glue_1.6.2
[37] farver_2.1.1 colorspace_2.1-0 fansi_1.0.5 rmarkdown_2.25
[41] purrr_1.0.2 tools_4.3.2 pkgconfig_2.0.3 htmltools_0.5.7