Subset Models for Multivariate Time Series Forecast
1st MulTiSA, ICDE 2024
2024-05-13
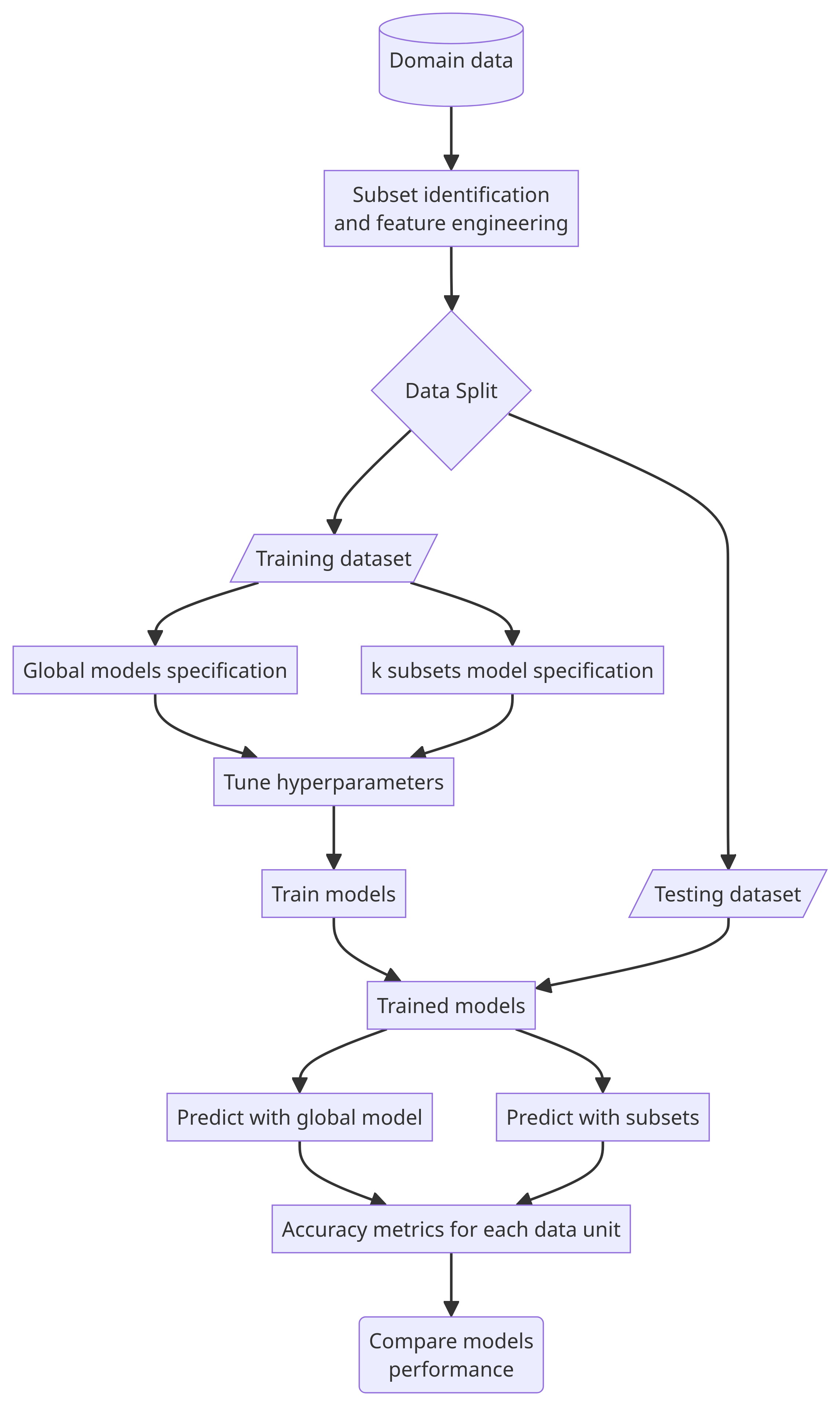
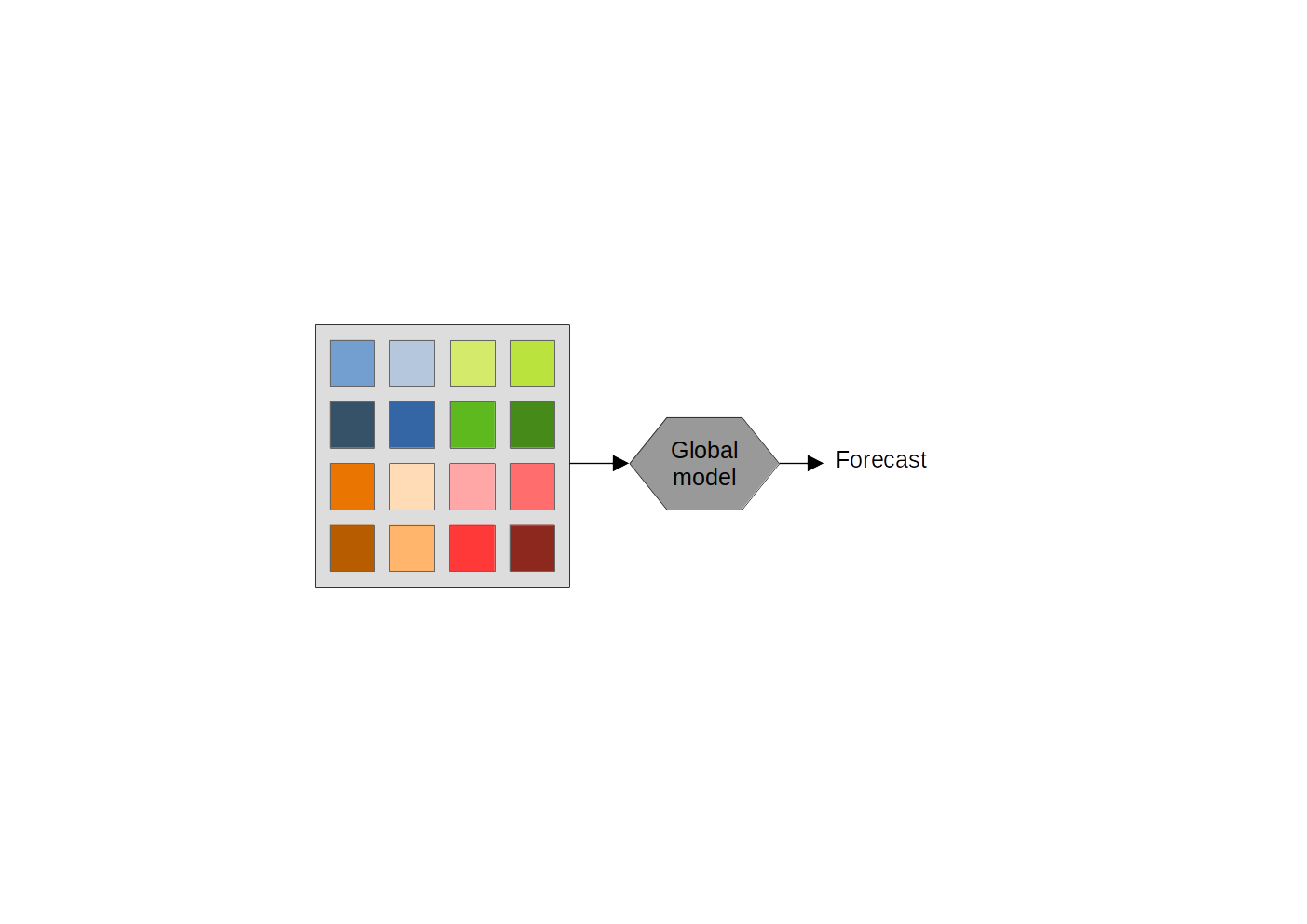
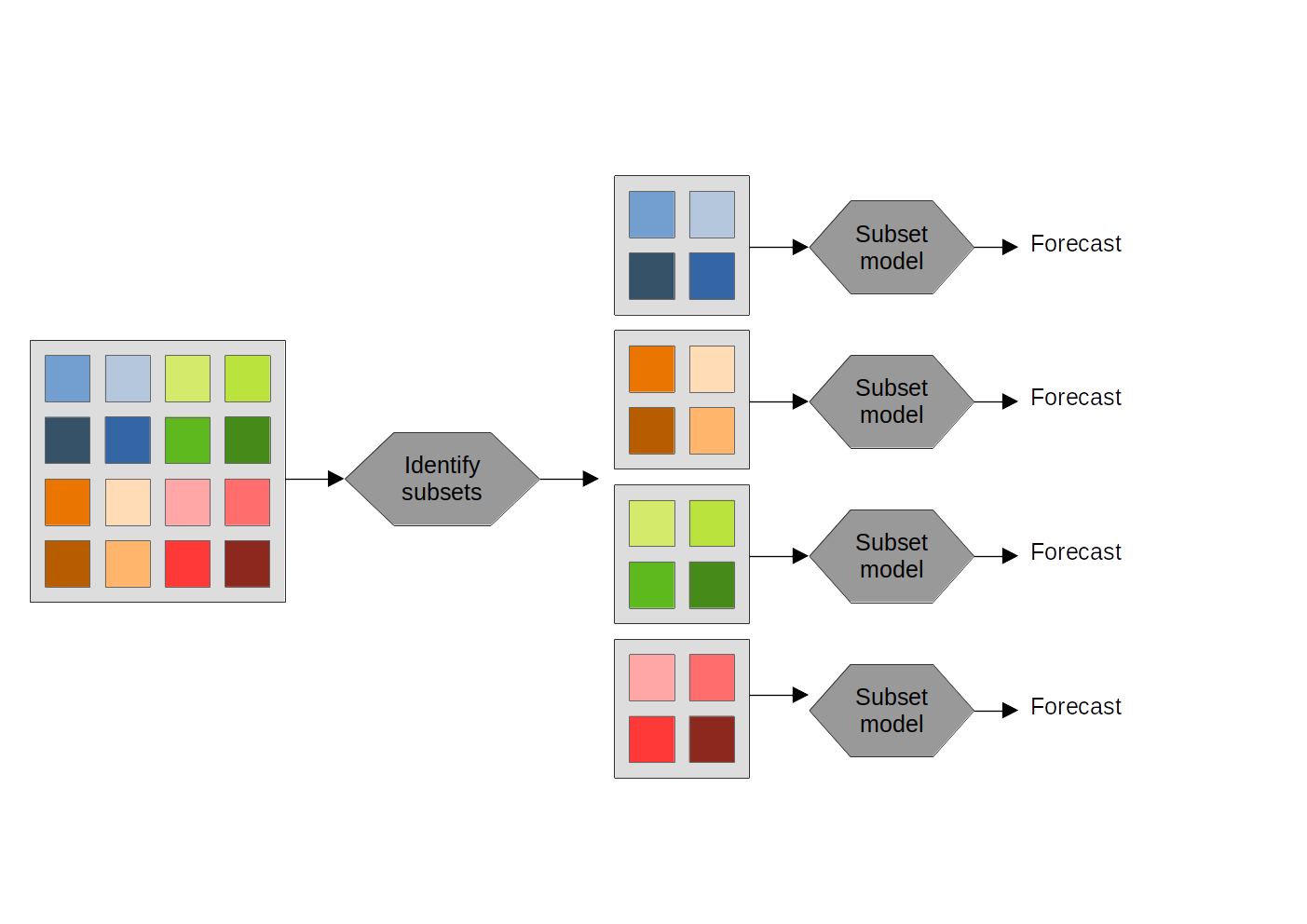
Subset modeling framework
- Identify subsets within the dataset with similar patterns
- Train models for each subset
- Use the model trained on the subset data for prediction

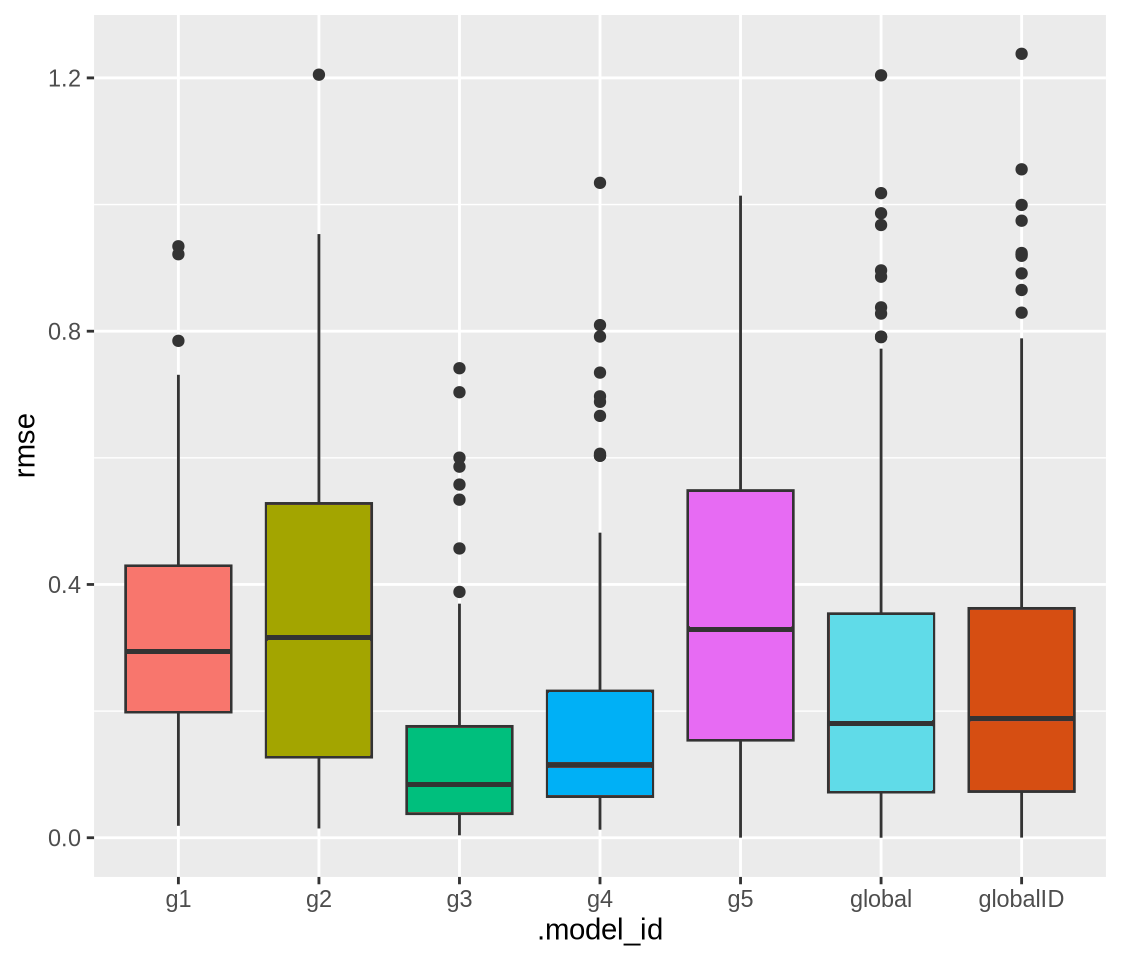
Clustering results
- \(k = 5\) returned the highest silhouette score
- Partition sizes: \(g_1 = 69\), \(g_2 = 62\), \(g_3 = 82\), \(g_4 = 102\), \(g_5 = 18\)

Model results