%%{
init: {
'theme': 'base',
'themeVariables': {
'fontSize': '30px'
}
}
}%%
flowchart LR
climate(Climate) --> vector(Disease vectors) --> health(Human health)
climate --> health
climate --> social(Social & economic \n determinants) --> health
Disease and climate data fusion for modeling
An application case for Brazil
2024-03-21
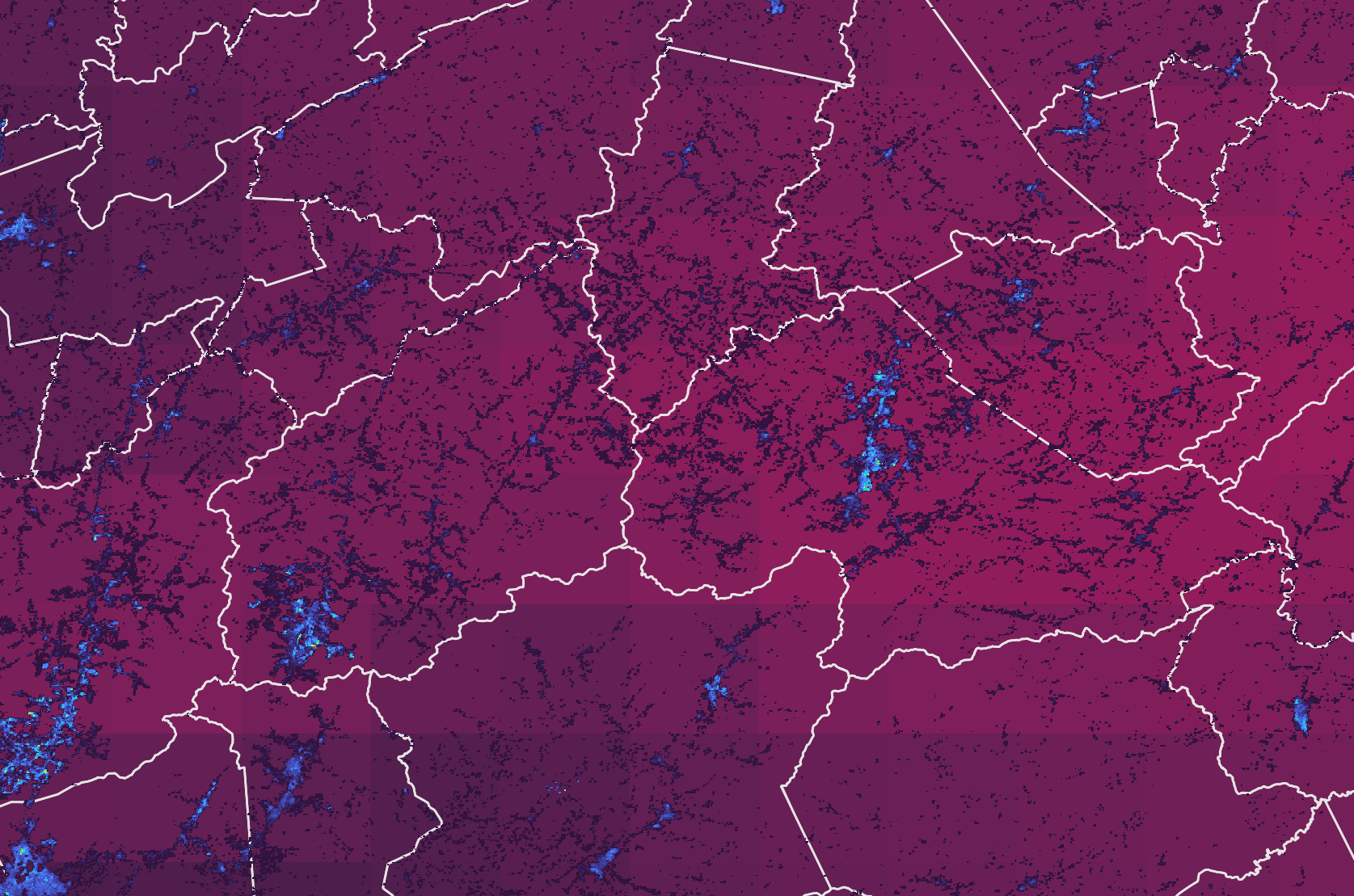
A time-lagged relationship
- Vector life cycle from a time perspective
- Climate conditions from the past leads to the disease incidence of tomorrow
ERA5-Land reanalysis
- Copernicus, ECMWF
- Global coverage
- Hourly data
- 1950 to the present (one week delay)
- Spatial resolution ~9km
- Several climate indicators
Data structures
- Climate indicators: grid data
- Disease incidence: tabular, individual cases aggregated by spatial regions and time spans

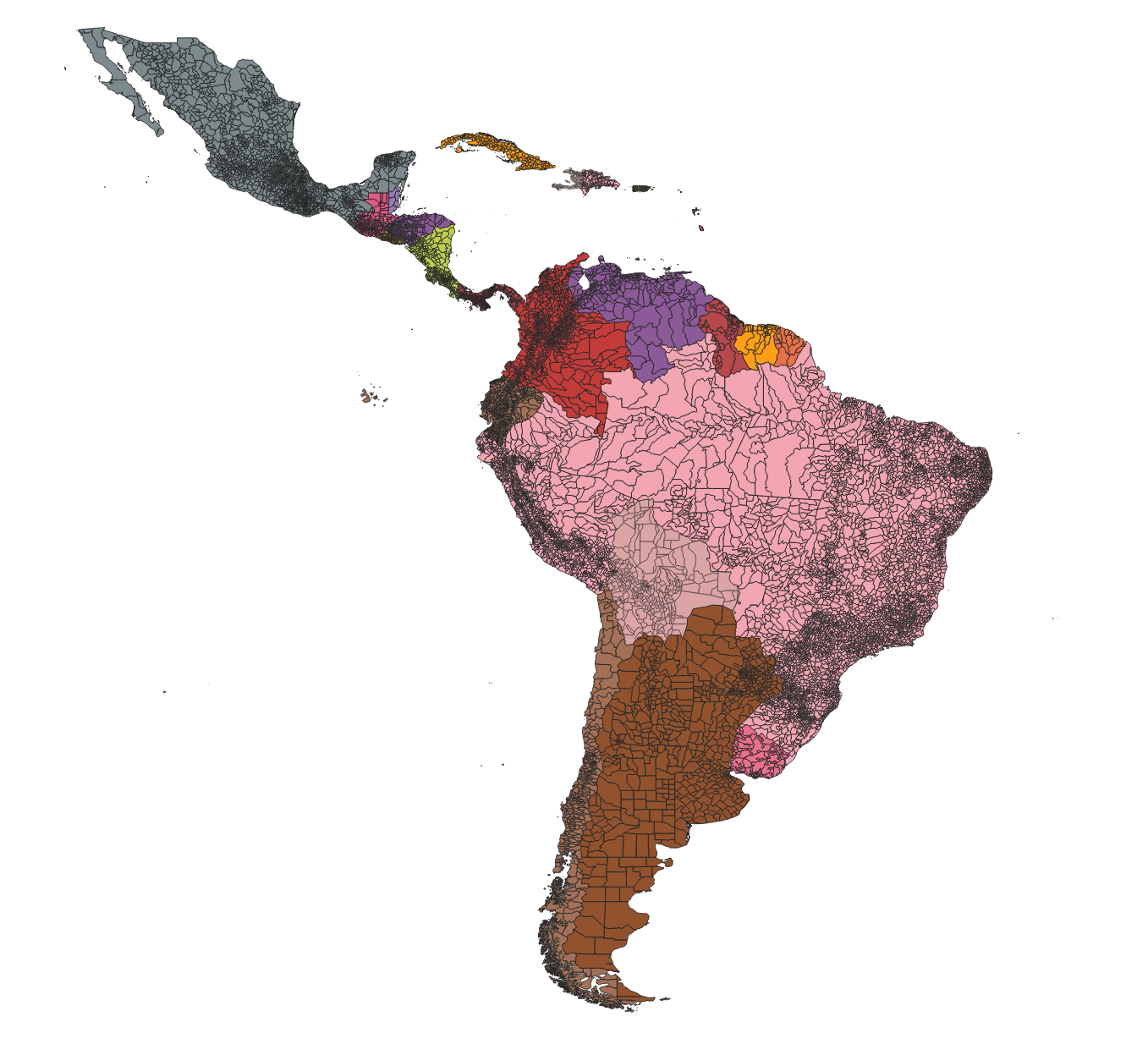
Fusioning data
ERA5-Land Daily datasets
- Open data, available at Zenodo
- 7,105 files, 658.7 GB
- Reproducible R scripts
- Plans to continuously update this dataset and add more indicators
https://rfsaldanha.github.io/data-projects/era5land-daily-latin-america.html
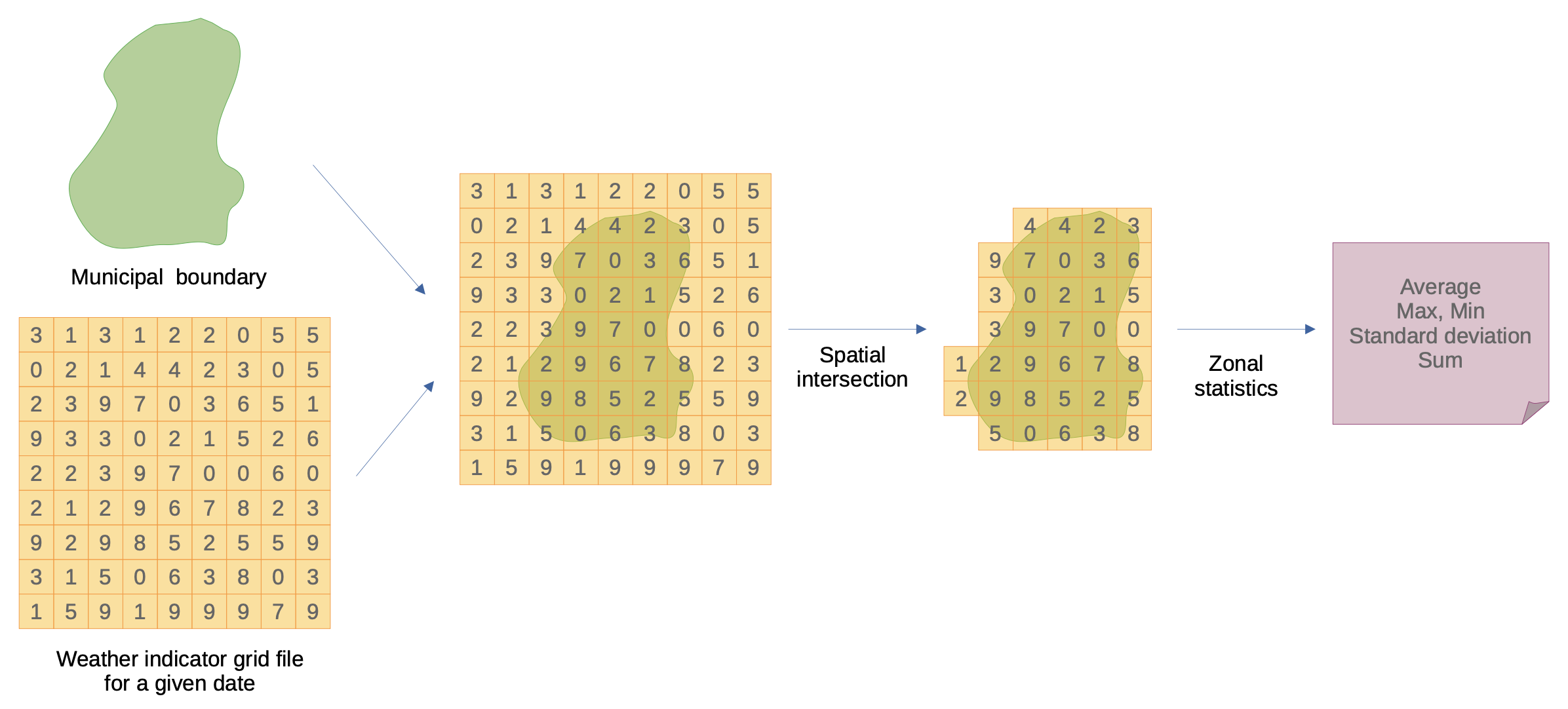
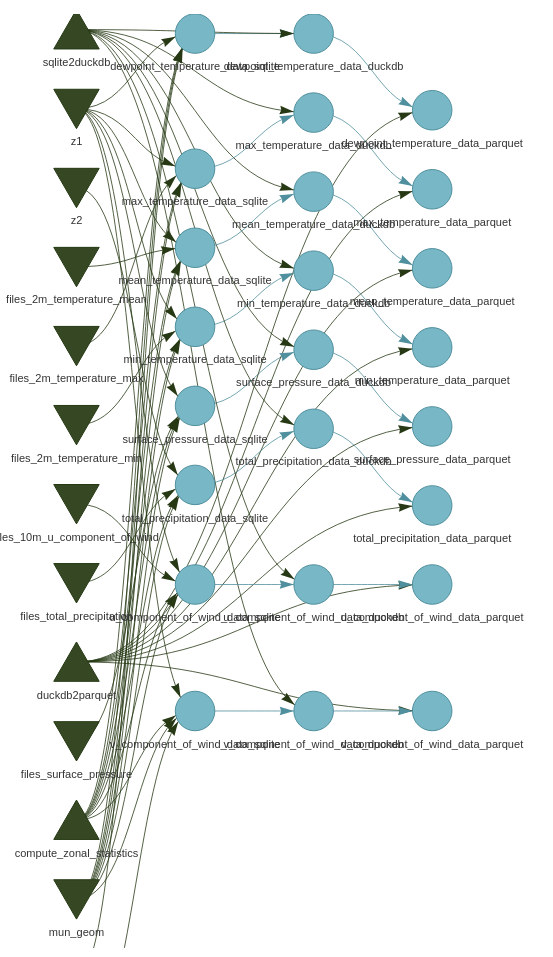
Zonal statistics
- Challenges to handle the amount of data and computational tasks
- Strategy
- Group the tasks into chunks and compute in parallel
- DAG (Directed-Acyclic Graph) approach to orchestrate computation, with the {targets} package
- Save results into columnar-oriented databases for fast data retrieval (duckdb and parquet)
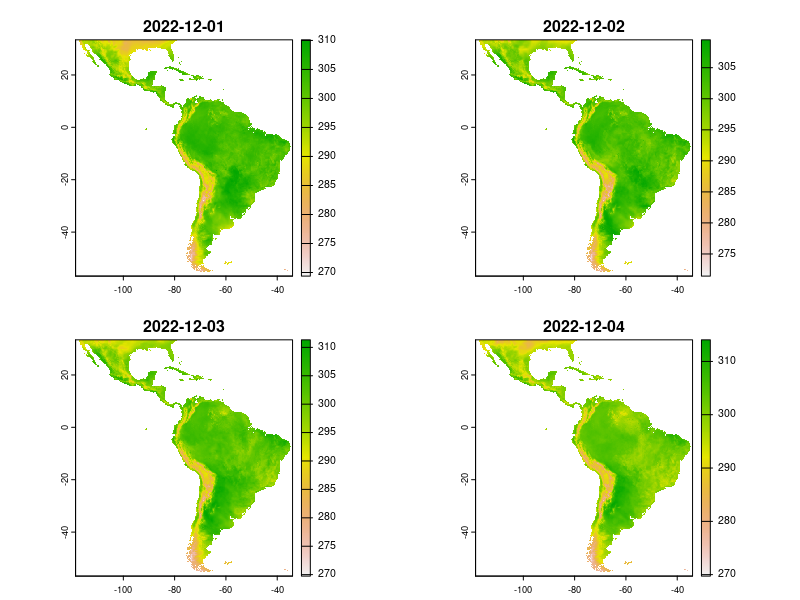
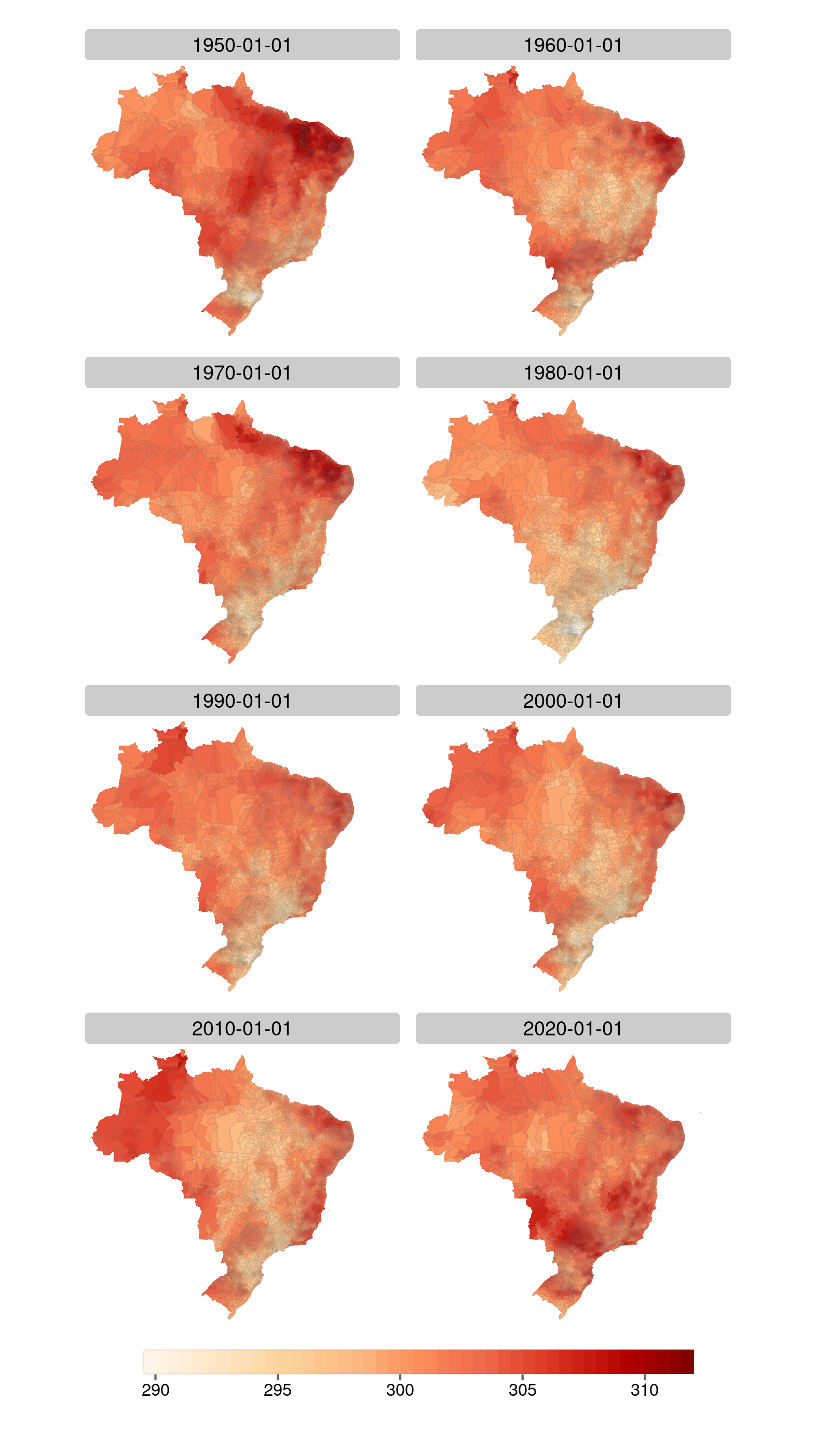
Temperature
Precipitation
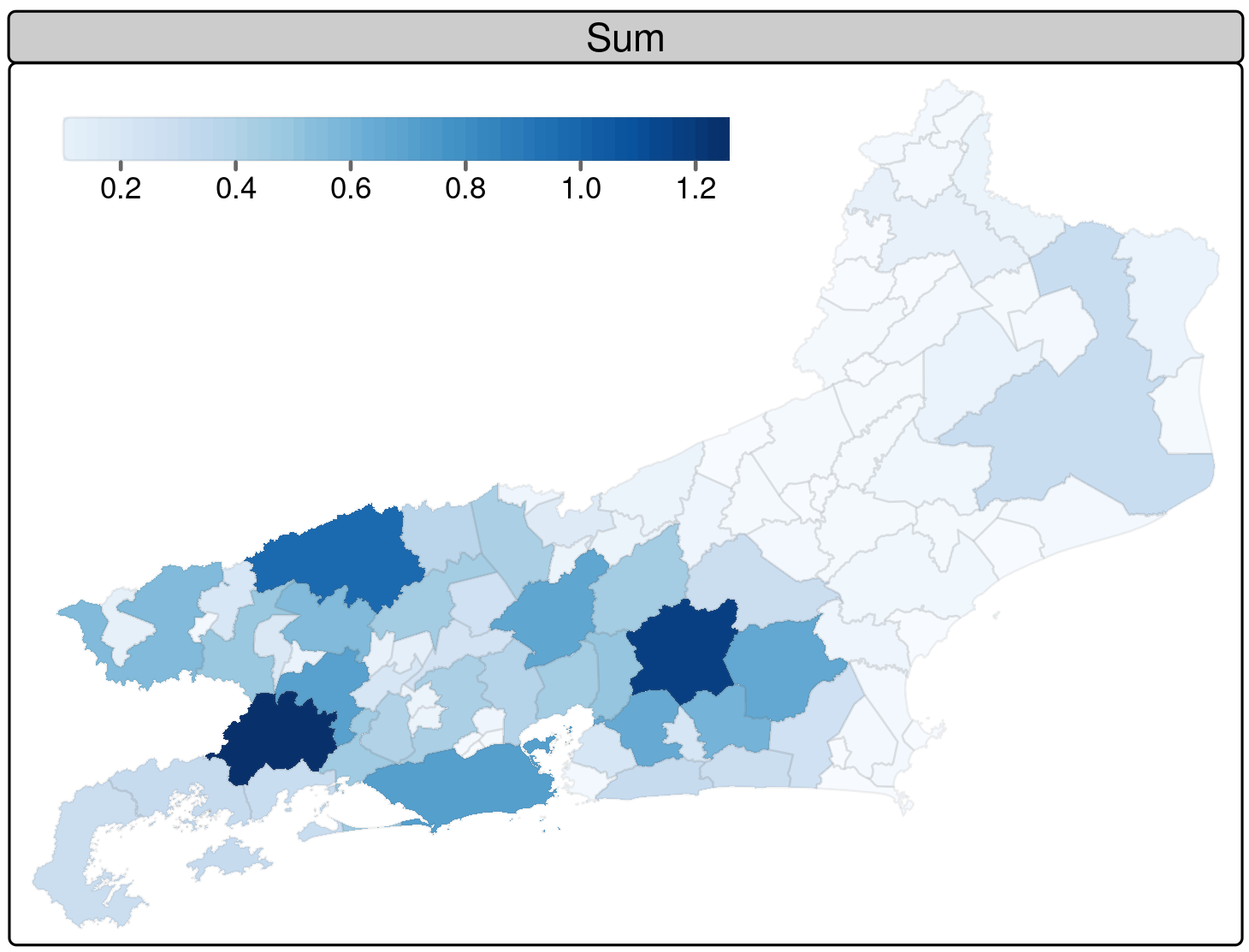

Rio de Janeiro municipalities. January 1, 2010.
Angra dos Reis

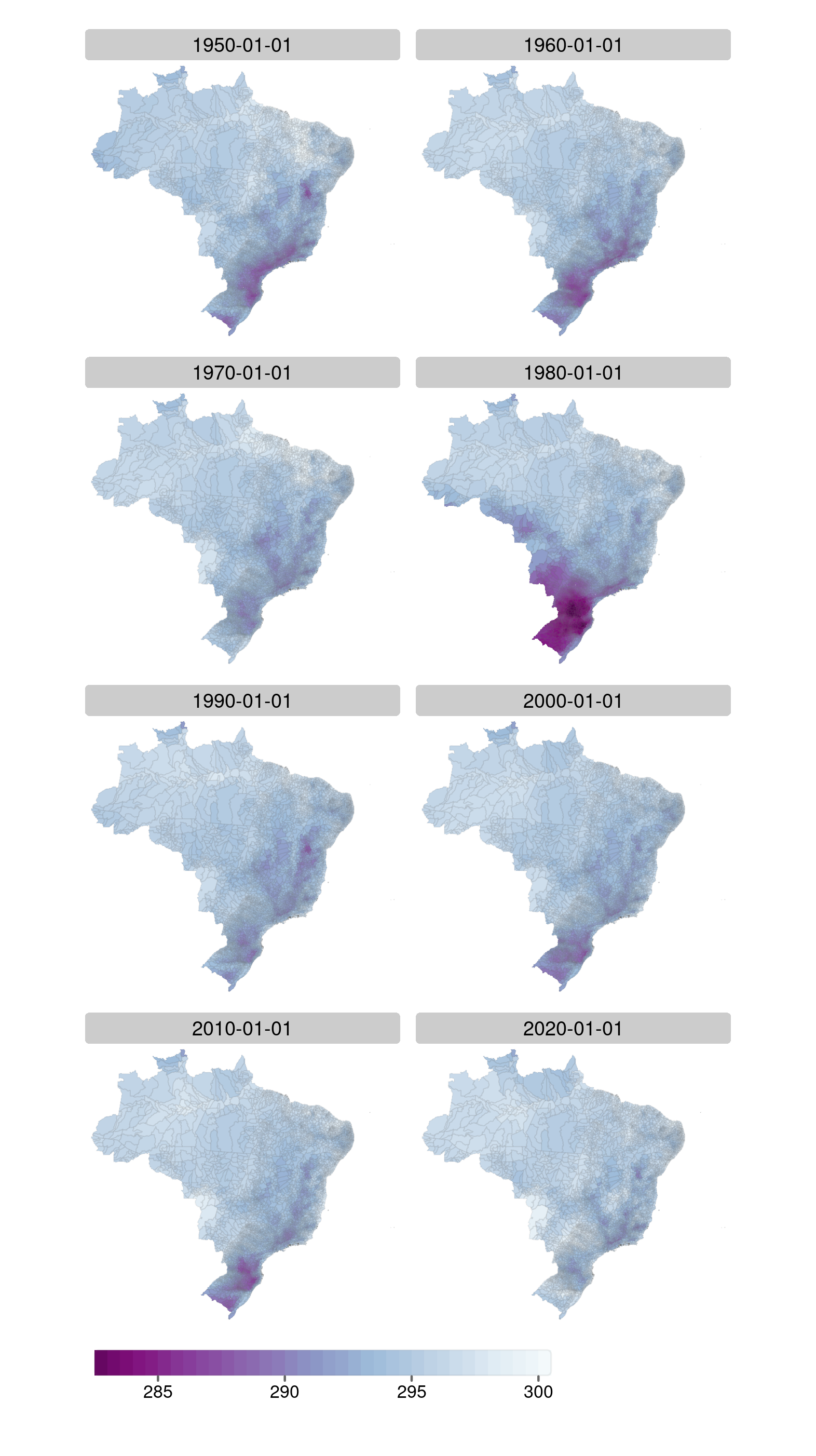
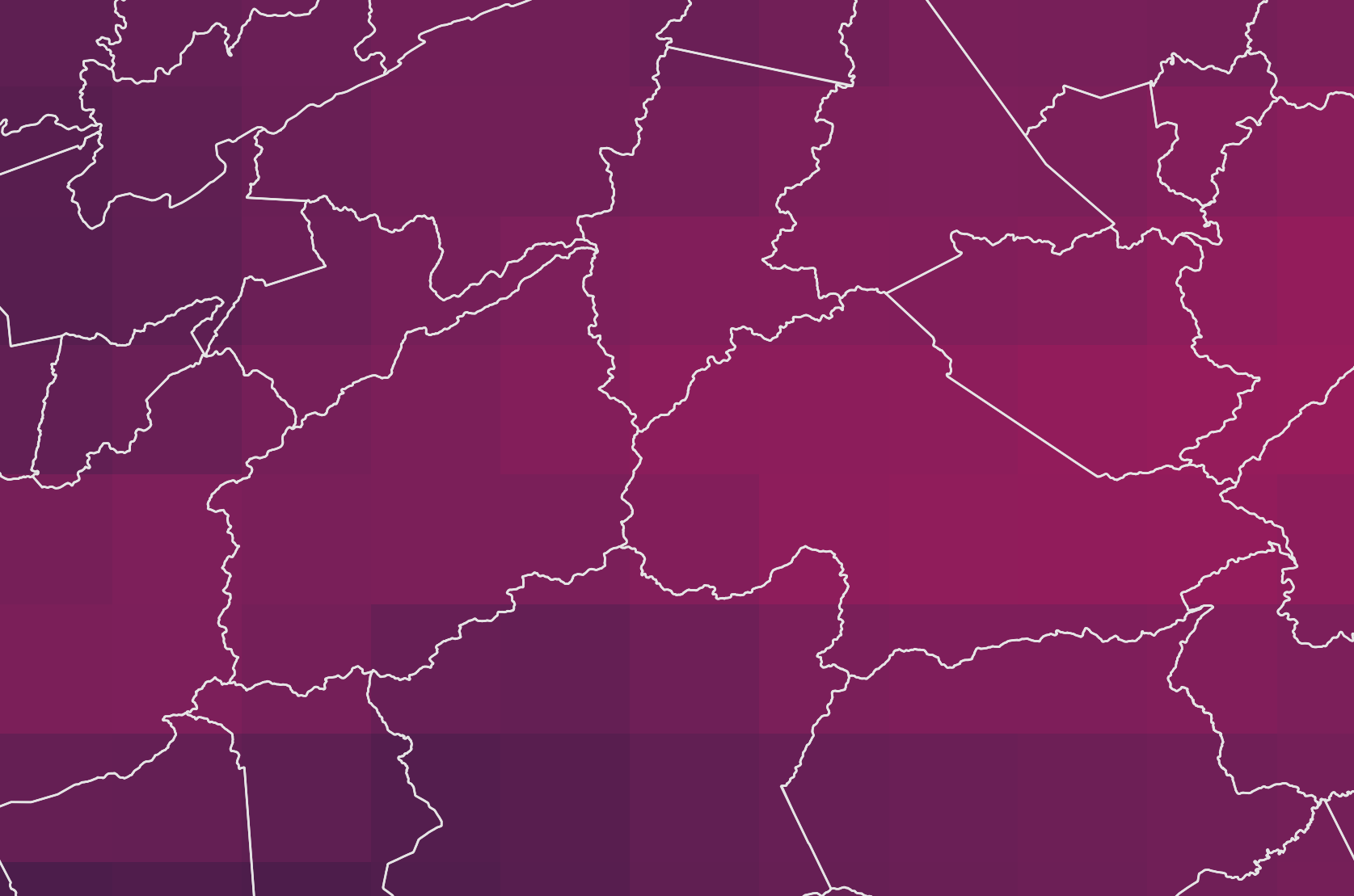
Resolution and spatial variability
- Brazilian municipalities size variation
- Altamira (PA): 159,533 km2
- Santa Cruz de Minas (MG): 3 km2
- ERA5-Land cell: ~ 100 km2
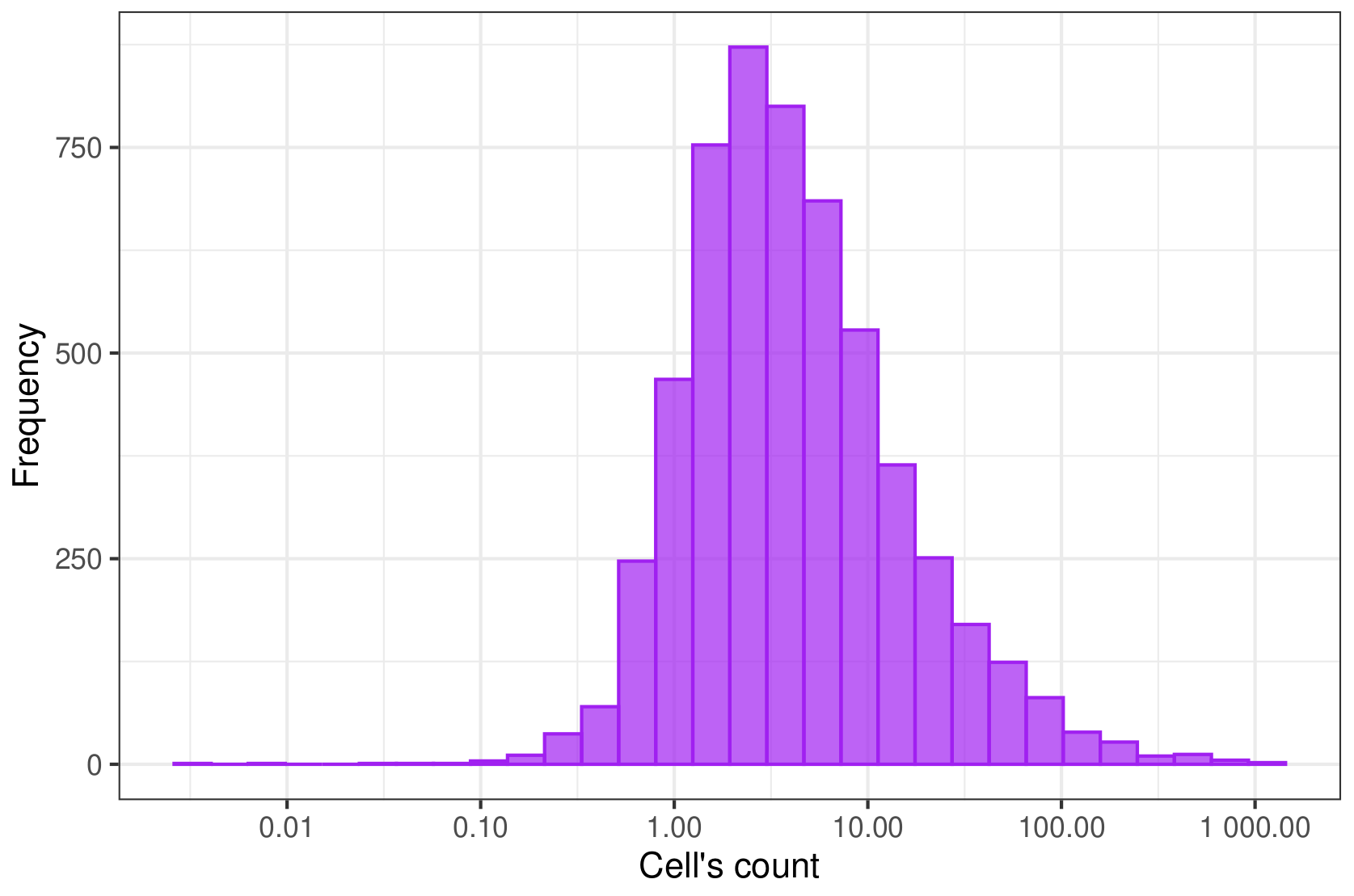
Published paper
- Environmental Data Science journal
- Published on February 8, 2024
- Journal’s most read paper of the month
- More than 9,000 datasets downloads on Zenodo so far
- Inria has an agreement for APC fees with the Cambridge University Press
- Swift submission process
![]()

brclimr R package
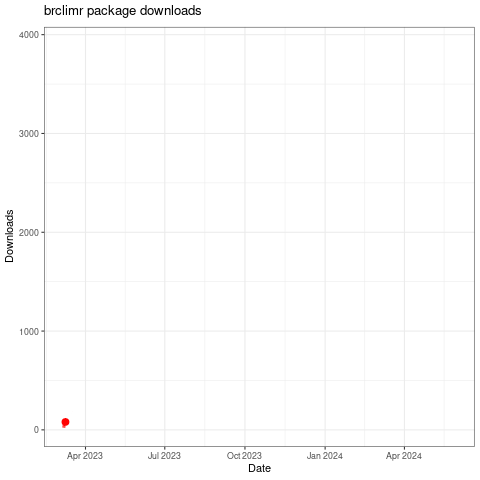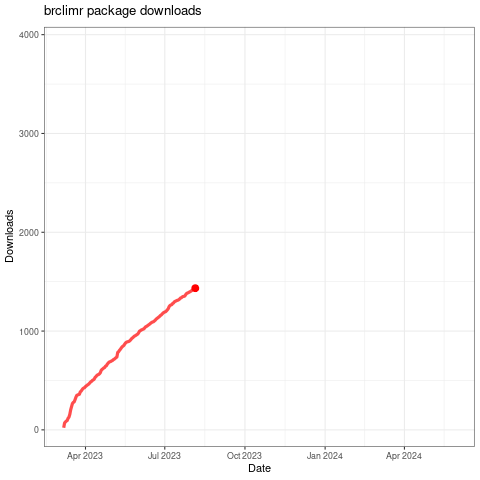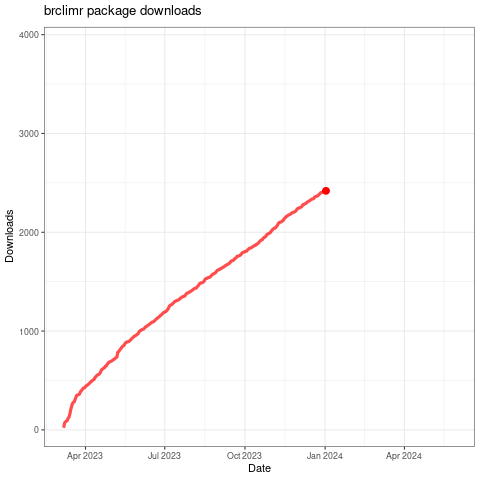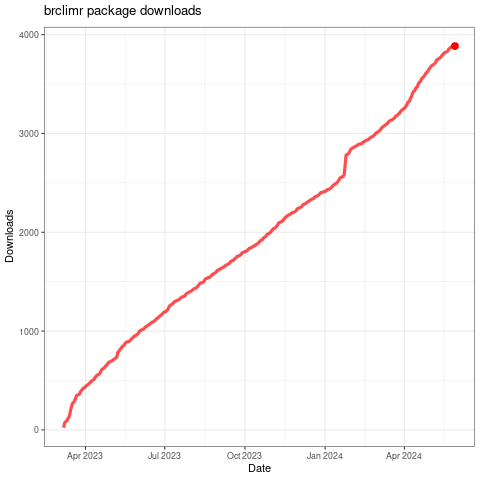
Usage
- Training multivariate machine learning models to forecast dengue incidence in Brazil with a subsets strategy
\[ {\small \begin{aligned} D_t = \mu + & \theta_1 D_{t-1} + \cdots + \theta_p D_{t-p} + \\ & \lambda_1 C_{t-1} + \cdots + \lambda_p C_{t-p} + \\ & \varepsilon_1 e_{t-1} + \cdots + \varepsilon_p e_{t-p} \end{aligned}} \]
- Cluster municipalities based on dengue spread and climate regimes
- Train different models for each partition
- Accepted paper on ICDE2024, Multivariate Time Series Analytics workshop
![]()

Next steps…
- Continuous update
- Human settlements, population-weighted zonal statistics
- Compute climate time-series features: heat waves, persistent rains, etc.
- Adopt climate products with finer resolutions when possible (CHIRPS)
- Expand results to other countries